

7 Questions Brands Are Asking About Agentic Commerce; Directly from My Digital Shelf Summit Workshop
Fresh from Digital Shelf Summit in Atlanta → the Top 7 Questions I was asked by large brands figuring out Agentic Commerce... WITH Answers!


Note: Brands pictured here were listed on the DSS website as speakers, but representative of the types and size of brands in the audience.
I was invited by the awesome folks at Salsify to attend the Digital Shelf Summit 2026 and to deliver a keynote at the opening day to ‘set the stage’ for the theme of the event.. you guessed it: Agentic Commerce. We had permission to record that and will be publishing it as a podcast next week, stay tuned. I also gave an interactive Agentic Commerce Optimization Workshop:

I started the session by going deep on one SKU, a Silk vanilla almond creamer, in what we call an Agentic Commerce Audit. This process illustrates the patterns that you start to notice patterns about how the engines talk about your products. You can take the positives and negatives patterns and apply what you learn in one SKU to every product in your catalog. The deep-dive stuff was fun, but the best part of these sessions is always the Q&A. Brands asked the questions that are actually on their minds → not strategy or theorticals but , the real tactical “what do I do Monday morning” after this conference questions.
Q1: How Fast Are LLM Training Cycles Moving?
The background for this question was part of my setup for the workshop. Part of ACO strategy for brands that don’t sell direct to consumer (commonly called 1P/Wholesale or B2B Brands) is to make sure their purely informational websites have all the correct metadata outlined in our ACO strategy (introduced here). While this doesn’t drive direct sales, the agents pull in the data that improves the product-level results from retailers selling their items. Because the 1P agents (Rufus/Sparky/TSA) are build on models like OpenAi/Claude/Gemini, they will pick up this data in their training data and it will go into ‘long term memory’.
With that, background, here’s the answer:
The training window is closing in faster than you’d think, and they’re accelerating. Training cycles used to be 18 months → then a year → now we’re at about six months for a foundation model refresh (Claude is here, I think everyone will catch up this next cycle).
And that’s just the base model. The RAG / web-index layer that lives at your 1P partner is the part that actually pulls in your fresh product content and that updates constantly. Anthropic, OpenAI, Google, Perplexity, CoPilot, META → they all have crawlers hitting your site in something close to real time.
Want proof of where any engine stands? Ask it directly: “What’s your training cutoff?” You’ll get a real date back. As of this writing:
ChatGPT 5.5:

Claude Opus 4.7:

Gemini 3.1 Pro:
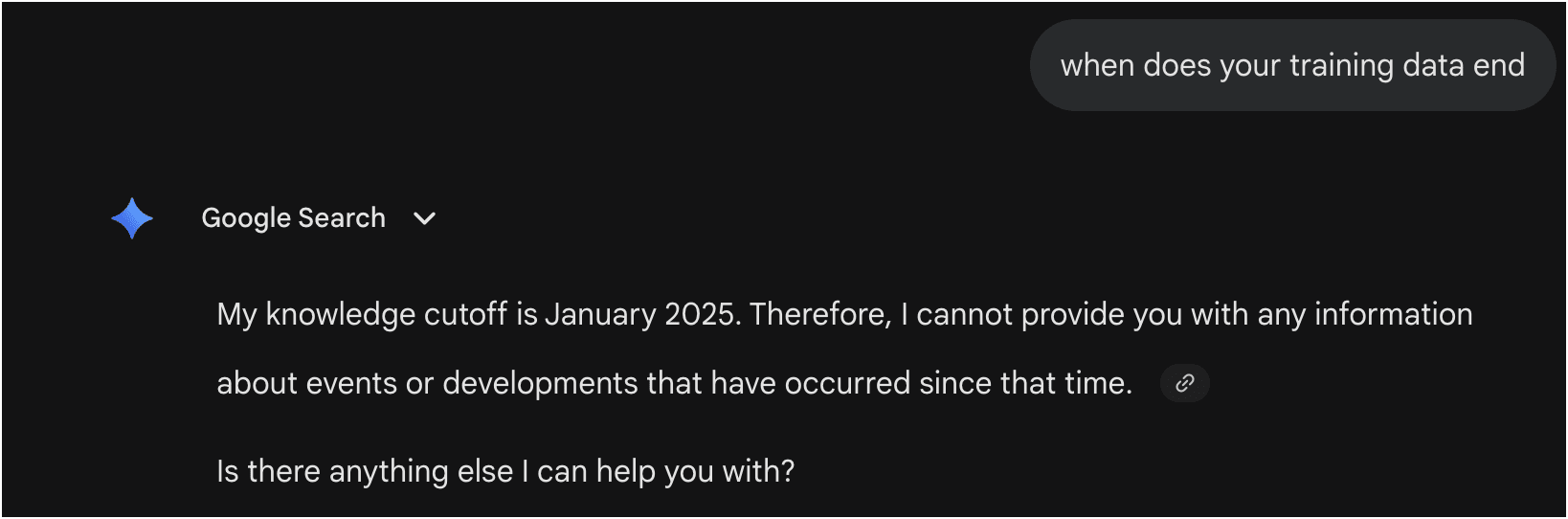
Takeaway: Belt and Suspenders: Publish to your content to your website for training data longer-term AND make sure you optimize what you send your retailers. This puts your product data in the ‘short-term’ memory and the ‘long-term memory’.

Q2: There are Two Schools of Thought: Flood the Zone With Brand Content (AEO/AIO) or Go Deep at the Product Level. Which is Right?
I’m going to sound like a broken record and we’re already on Question 2, but, you guessed it - you should do both.
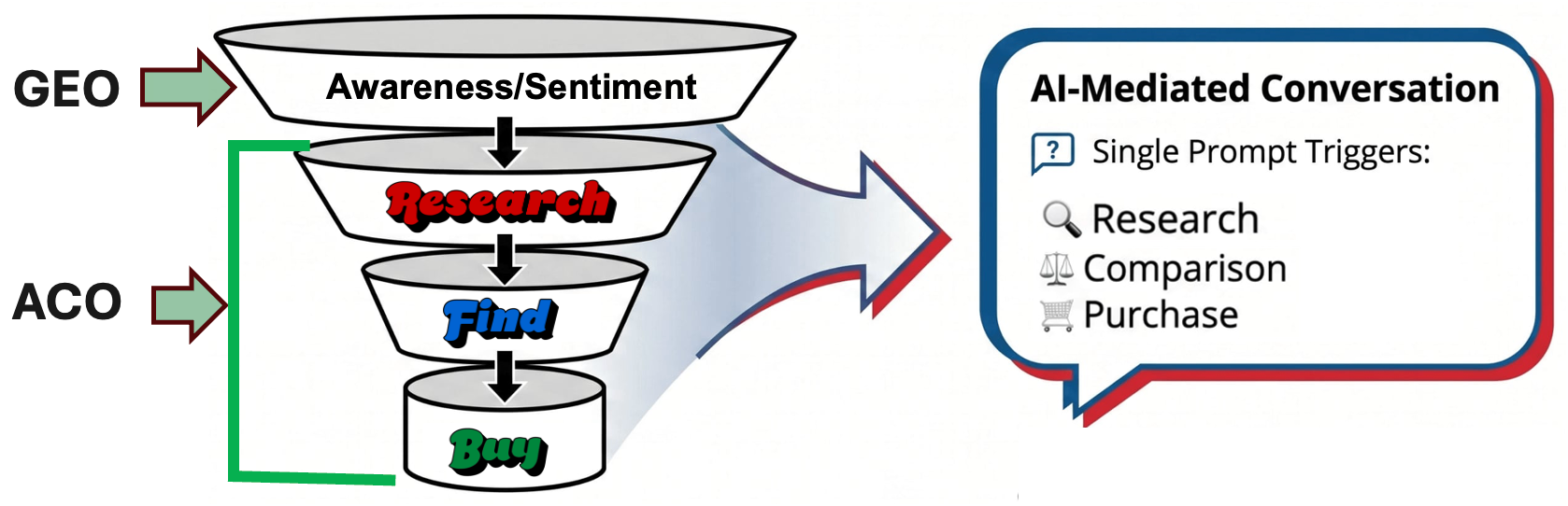
AEO/GEO is the awareness/sentiment piece - usually managed by your PR/marketing/brand team and not product-level content.
ACO is the product-level where you make sure your product-level content is beefed up for the LLM era and you’ve optimized it over several iterations across your 1P agents and the big 6 answer engines. This optimizes the part of the funnel involving products, and thus your product catalog: Research→Find→Buy.
AEO gets your brand mentioned in the conversation. Product-level optimization gets your SKU onto the offer card. Two different pieces of real estate, and you want to win both.
The AEO-leader, Profound, style of “pump out a thousand pieces of brand content” approach is directionally fine. Brand-story level content builds the brand-mention (sentiment) layer. But if your Attributes, supplemental attributes, reviews and FAQs, distributed viadata feeds aren’t in shape, no amount of brand-level content saves you when a shopper says “I’m remodeling my kitchen and need a built-in espresso machine.”
The best news is ACO is both more actionable and faster to see action, and thus more measurable too.
Q3: What about Grok? Does it have a merchant center yet?
Not yet. Here’s the scorecard as of now →
ChatGPT → has one, it’s still gated, but should be open for online signup soon.
Gemini → The existing Google Merchant Center
Copilot → has one tied to the Copilot merchant center.
Perplexity → has one-ish, routed through PayPal, a little squishy on how to get access - there’s some chaos over at PayPal these days and merchants are getting mixed messages and delays.
Anthropic → rumor is working on it, nothing announced.
Grok → nothing.
But I’d bet on Grok showing up to this party. The infrastructure is too obvious to skip, and X is too motivated to monetize. Give it two quarters to get through the API.
Q4: Are Retailer Walled Garden Agents like Rufus and Sparky Bleeding Signals Back into the Open Agents (ChatGPT, Gemini)? Can Optimizing for one Hurt the Other?
Yes, there’s cross-pollination - but it doesn’t go this way, it goes the other way. Because these are walled-off retailes
Rufus is most likely a Claude derivative sitting on Anthropic’s model. Sparky sits on OpenAI’s model. So when you optimize for ChatGPT, ~90% of that work is automatically lifting Sparky too. Same foundation model, same eating habits. When you optimize for Claude, you’re long-term (training data) getting benefit in Rufus.
A large % that is additive is the retailer PDP and behavioral signals. Signals like what shoppers actually click, search, and buy inside Amazon or Walmart. That part you can’t reach from outside.
So yes you can feed the foundational models, the foundational models feed into the models underneath the retailer agents into their long-term memory. Then your PDPs come into their short-term memory.
Q5: How do you Optimize for a Retailer that Doesn’t Have an on-site Agent yet - A Grocery Retailer, for example?
Manually, retailer by retailer. For now.
You have to partner with your retail partners and ask them: “Can I add an FAQ block to my PDP on your site? Can I push metadata to the PDP? Can I expand my product description fields? Every retailer’s PDP is, at the end of the day, an HTML page. There’s always a way to inject the content the agents will want.
The good news: I’m calling it: every major retailer will ship an agent within ~12 months. Albertsons is out. The Krogers, Targets, and Lowe’s (grocery) of the world are all heads-down on this. → This is a problem that’s actively solving itself.
Do what you can today. The surface area expands automatically.
Q6: Do we really have to supplement each retailer’s “agent diet” by hand?
Short answer - for the next few quarters, yes. But here’s the framing that changes that math:
Your website is doing 80% of this work for you. The engines crawl your DTC site, ingest your metadata, pull in your FAQs, digest your reviews, and forklift all that data into their vctor databases. That index then powers every agent downstream, retailer-owned or not.
When those agents do launch, it’s largely going to inherit the product intelligence you already published on your own site. Also, everything you do today, will pay further dividends down the road because everything your organization learns about ACO will apply to LLMs now and into the future. The underlying love of natural language won’t change.
For a non DTC brand your website went from a 1 to a 9.5 on a scale of 10. It’s not a vestigial brochure anymore. It’s the source feed for the entire agentic ecosystem.
Q7: 🤯 How do you Handle AI-Generated Fake Reviews? How do you Even Know What’s Real Anymore?
This is the gnarly one, and it’s getting worse fast. Three angles →
(1) Verified-purchase signals → Tie every review to a real transaction, the Amazon model. By far the strongest verification of a review, and the hardest to fake. If you’re not running DTC, lean on retailers who do this well.
(2) AI-detection tooling → There are services that score text for AI-generation probability. They’re imperfect but improving. Your review platform (e.g. Bazaarvoice, PowerReviews, Yotpo) should be building this into their stack right now. Talk to your rep and ask what they’re shipping.
(3) Owned content as anchor → When the review pool gets polluted, your owned, brand authoratative content (FAQs, structured product data, schema.org metadata) becomes a bigger share of the engine’s truth. The brands that invest heavily here are building insulatation.
The bigger picture? Review trust is going to get harder before it gets easier. Brands with verified-purchase ecosystems and strong owned-content programs are going to dramatically outperform. Plan accordingly. Start today.
These seven questions map directly to where every brand should be focused right now: training cycles, AEO vs. product-level, engine coverage, cross-pollination, prompt engineering, retailer agents, your DTC site as foundation, and review integrity.
Stay tuned for incoming news on this broader topic later this week 🤫 🚀