

Battle of the Agentic Browsers Update: Microsoft Edge enters the Ring with Copilot Agentic Assist - Part 1/2
In this two part series we go deeper into Agentic Browsers and then pit Agentic new entrant Microsoft Edge against incumbents Dia and Comet.

Welcome to Part 1 of our deep dive into Agentic Browsers. In the first part, we’ll summarize everything that’s happened and predicted with Agentic Browsers and go over the architecture of an Agentic Browser and how it’s fundamentally different than what we call Agentic Shopping. Then in Part 2, we’ll do a bake-off between three browsers: Dia, Comet and the new browser on the block: Microsoft Edge with Copilot agentic assistant.
Welcome to the Agentic Browser Wars

A couple weeks ago we announced that ‘The Agentic Browser Wars’ had begun iand I talked about how Agentic Browsers are the natural progression in Agentic Shopping because they have the ‘high ground’.
Microsoft Edge with Copilot Assist Enters the Arena
Monday, July 28th, Microsoft announced that their state-of-the-art (SOTA) browser, Microsoft Edge now had a Copilot Mode which gives it an ‘in browser agentic assistant. You can download Edge for free for Mac or PC here.

What Microsoft is done is plopped their AI into Edge and given it access to all the things a browser normally sees and mixed in agentic capabilities.
Agentic Browser Wars Players and Timeline
With Microsoft Edge here today, it’s a good time to review all that’s happened. It’s crazy to think that in 30 days we’ve had three big new Agentic browsers drop!
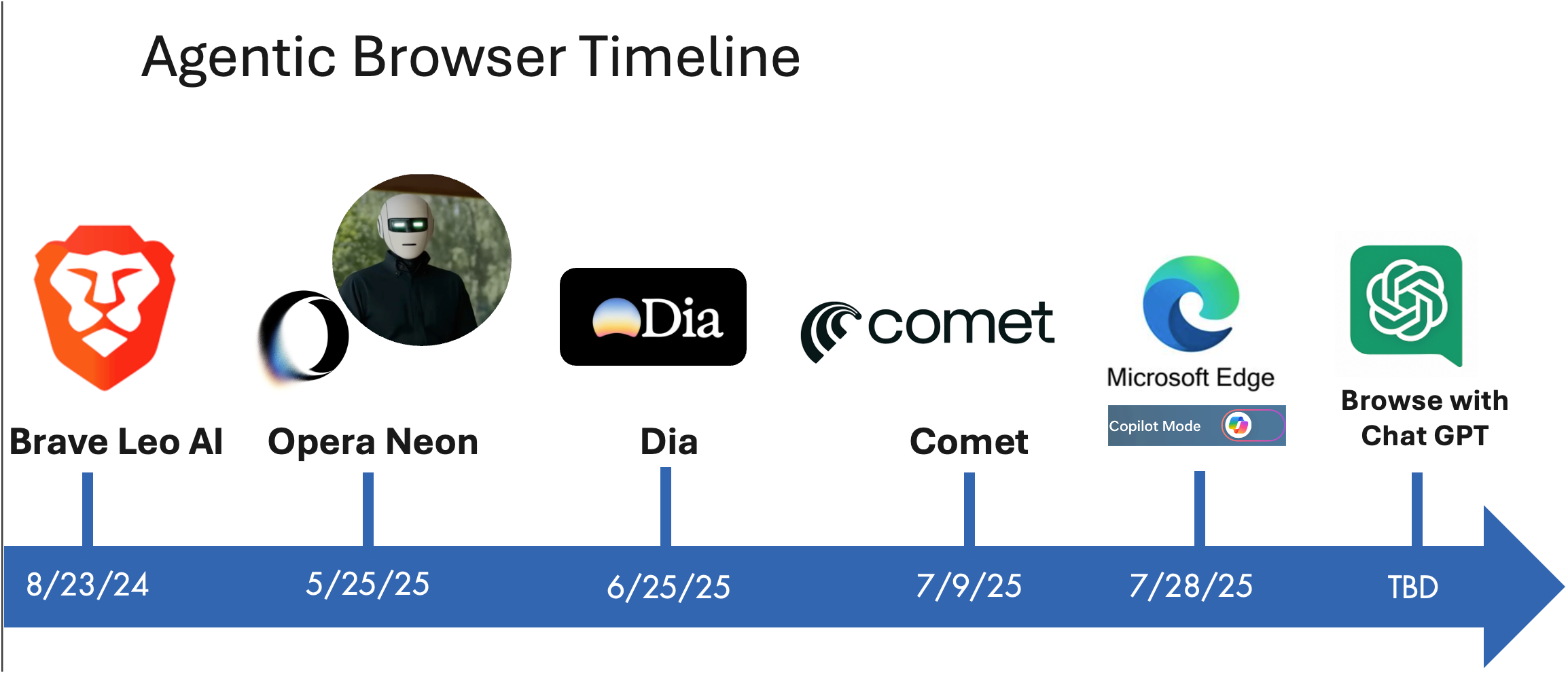
Waiting in the wings…
We’re still waiting on ChatGPT and Google to see if they enter the melee and when. I predict by 10/15/25 we have those two in our hands, 2.0’s of Comet and Dia plus some surprises. Welcome to AI Time!
Why do You Say: “Agentic Browsers Have the ‘High Ground’ “?
I went over this ‘High Ground’ thesis quickly in my Comet livestream, but since then I’ve gotten a ton of questions about it so wanted to provide more context and lay it out more clearly and in writing.
Note in these graphics I use Perplexity as an example, but it’s the same for any Agentic Browser.
How GenAI Web Search Works
First, let’s level-set and look at how a model GenAI system with Web Search works
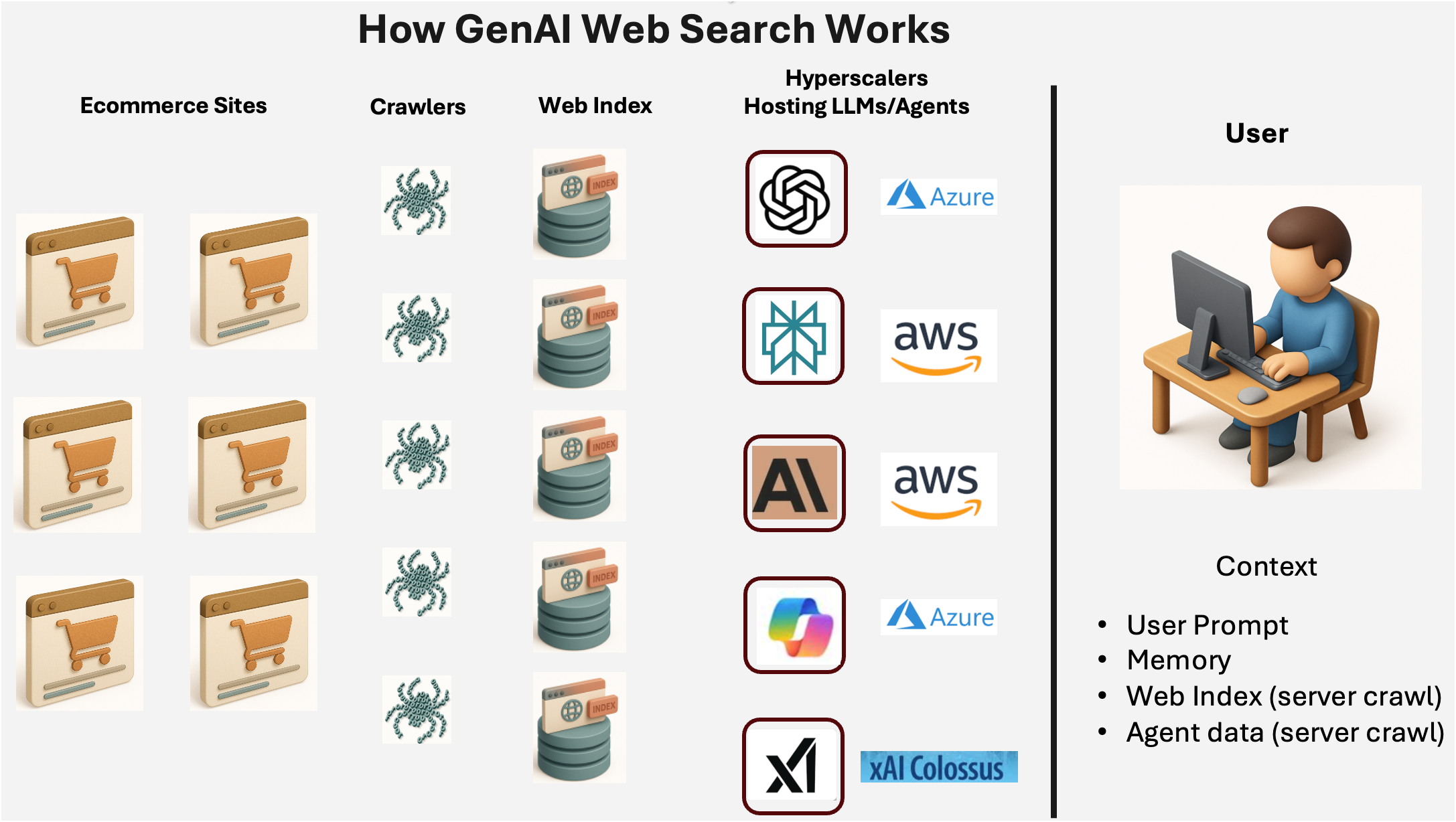
Here we have the big 5 and show the hyperscaler (cloud servers) where they ‘live’. Your general ‘big 5’ (note Meta is very behind so we left it off) ChatGPT, Perplexity, Anthropic, Copilot, and xAI.
These systems have two databases they use:
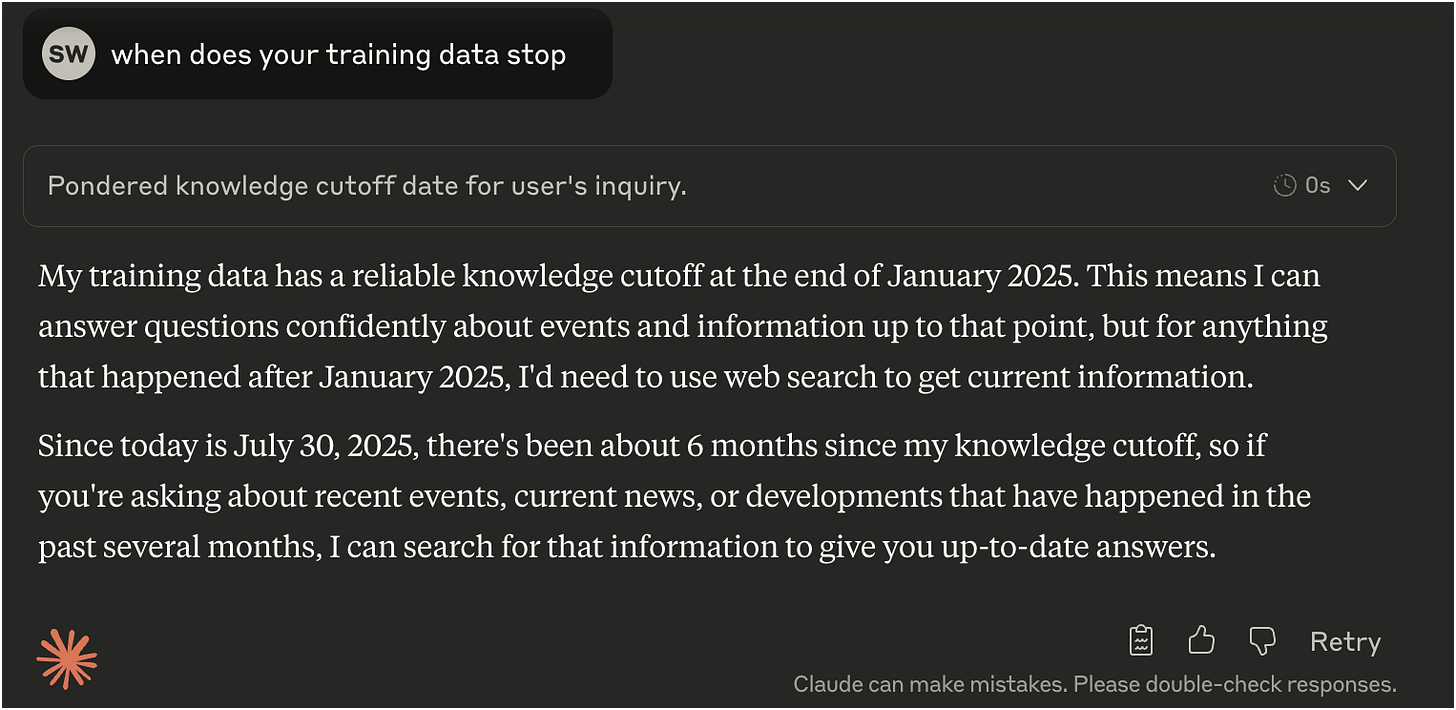
Training data (knowledge) - All engines basically train on a massive database of data - basically the entire internet, all the books they can get, etc. While this isn’t ‘stored’, it’s what the LLM learns from. In our world when you ask the LLM about a product, it has seen every review, every PDP, etc. The key point to remember about training data is it takes so long to train a SOTA model that there is always a cut off. You can ask any LLM and it will happily tell you. For example, here’s Claude Sonnet 4:
Web Index - That’s where the Web index comes in - the web, and especially ecommerce is a highly variable, always changing set of data (new products, in/out of stock, pricing, promotions, etc.) so the engines augment the training knowledge with a traditional Google-esque web index. Web indexes can be very current depending on the use case, but in general are days old whereas training data is many months old.
Crawlers (aka bots, spiders or web data extraction) are a key component of both training data retrieval and web index building. What you do is you send a machine-driven browser to ‘look’ at web pages, load the data and pull out what you want and store it. This is a key component to the internet since the earliest search engines were born. You’re probably familiar with googlebot, their primary crawler that everyone in SEO-land spends tons of time trying to outsmart and out maneuver.
The key point here:
Training day - months old, builds LLM underlying knowledge
Web index - days or weeks old - for more current information
How Agentic Commerce w Web Search Works
Agentic generally creates a new problem - instead of just getting the GenAI system to retrieve information for us which is ok generally if it’s days or hours old (what i’d call ‘read only'), we know want to give the GenAI system a tool do stuff on our behalf (read+write). Now we’re going to need real-time information. Enter the third player in our architecture - the Crawler-enabled Agent.
For Agentic shopping, we are going to need a fourth component, a product catalog:
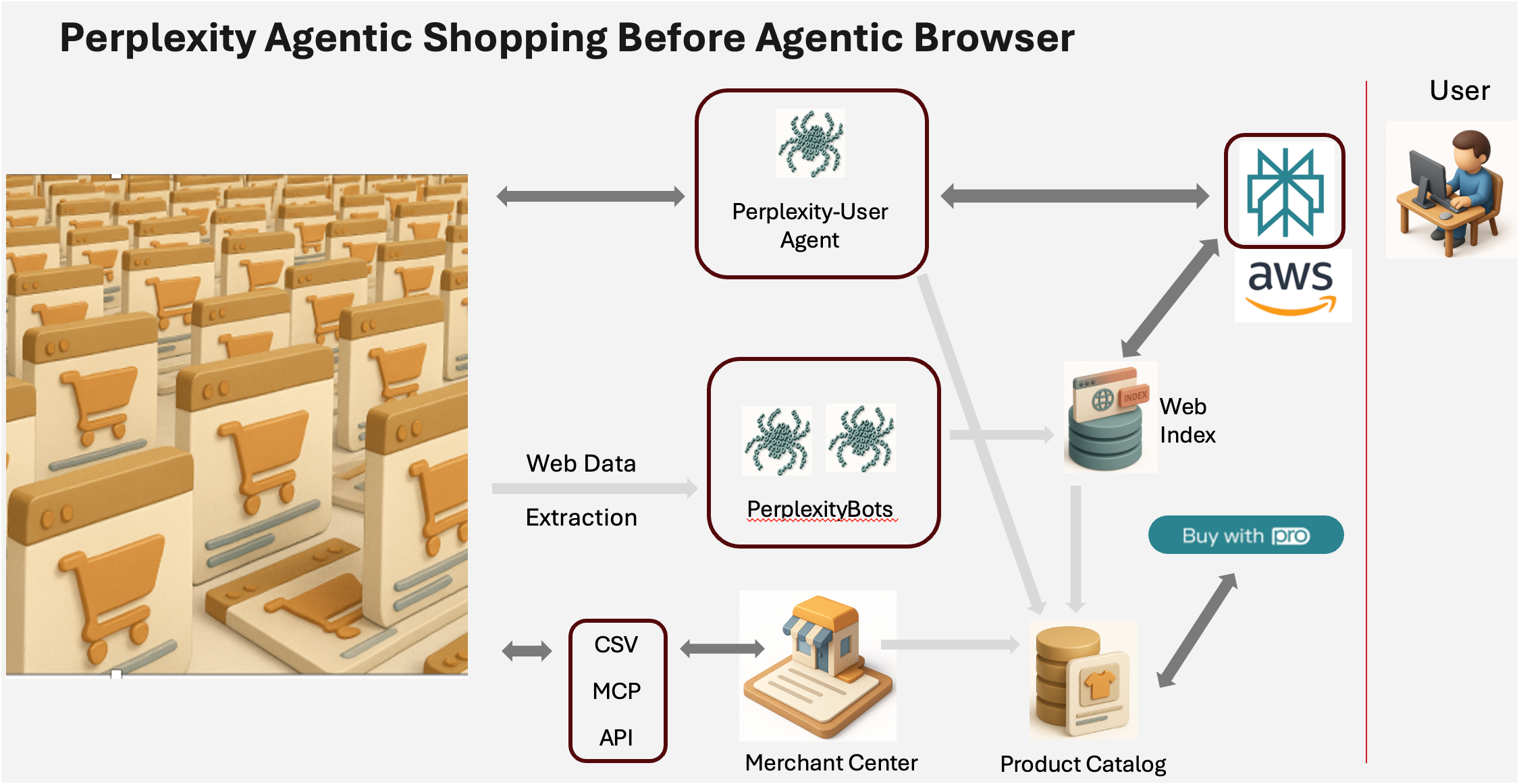
The Crawler-enabled agent can, in real-time, go visit a site, ‘read’ what it sees’ and then do things exactly like a human would such as enter text in fields, drag and drop, press buttons, etc.
The product catalog is interesting and an area of a lot of innovation. Most Agentic Shopping solutions start with a product catalog that is derived off the web crawl database - pulling out the product information (offers), canonicalizing it (matching it) and sorting it into a database of ‘golden SKUs’ and the corresponding offers. It turns out this is extremely hard if not near impossible from a web crawler, thus many Agentic Shopping Engines have also opened a ‘merchant center’ where retailers and brands can send in a datafeed of their products to make sure the Agentic Shopping Engine has the best data.
In retail, the Google Shopping Product data spec (usually in an archaic csv format) is the lingua franca (common language) of ecommerce.
To summarize we now have:
Training data - The entire Worlds data but months old, foundation of LLM’s knowledge
Web index - Index of the web, days old.
Product Catalog - Built from Web index and merchant center - gives the Agentic Commerce system a complete database of products including availability and pricing. Usually no more than 24hrs old.
Crawler-enabled agent - Server-based agent is able to get real-time information and manipulate web pages as a human would to achieve various objectives.
Putting these 4 together:
I want to buy a pair of shoes. I enter a prompt: “I’m looking for a Men’s size 11.5 merrell moab 3 in brown”
The Agentic Shopping Engine, uses it’s trained knowledge on shoes, the context I’ve provided in the prompt, the web index and the product catalog to find the best product for me. The more perfect that product catalog, the better the experience** (Foreshadowing ALERT! Product Catalog is super-important and will be a recurring theme and is the source of most immaturity in the Agentic Shopping world today).
As the user narrows their selection, in the background an agent may go and double check the availability and price of the product and perhaps start a checkout to understand the shipping and taxes.
Once the user picks the product they want to buy the agent, then goes and completes the checkout and reports back to the user.
All four lego blocks work together to provide a novel user experience.
Blocking Agentic Shopping
Now, let’s say you are a retailer and you do not want people to shop this way because you want to have a direct relationship with them. For example, Amazon and Shopify are making moves in this direction. Because all this traffic is:
Identified - Perplexity’s bot identifies itself as ‘perplexity-user-agent’ and is easily blocked.
Coming from a trackable server - Server-based agents also come from a bank of servers with IPs ‘known’ or traceable to be owned by Perplexity, and are also easily blocked.
It is blockable and is actively being blocked by a couple of sites. (I disagree with this strategy, but to each his own).
In addition to being blockable, the other weakness is the agent lives all alone out on a server, it gets some context and intent from the prompt and what not, but it sees a tiny little window into what you are trying to do. Remember - LLMs LOVE context.
How Agentic Browsers Work
Now for the final step in our progression of these innovations (keep in mind most of this stuff is under 2yrs old if not 1yr!) - the Agentic Browser.
What happens is we have all that Agentic Shopping Engine architecture described above and we add a couple of new twists:
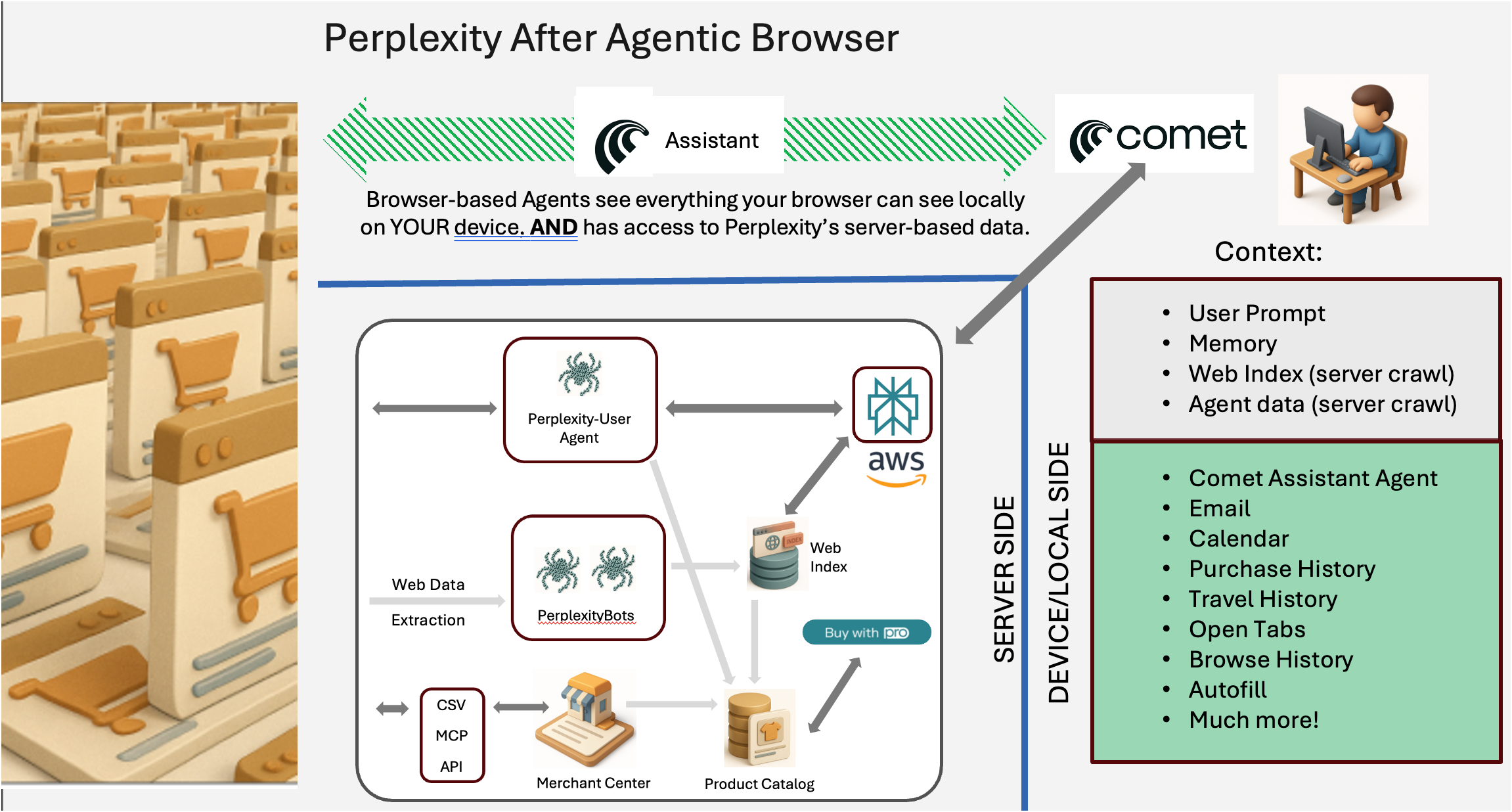
The first addition is another Agent - this one lives in the browser and, most importantly, operates locally - it is running on your computer. This is not to freak you out - it’s safe, you control what it has access to and it’s not a process or memory hog (your pre-agentic browser is doing much heavier stuff than this guy), but as you’ve probably figured out this makes it near impossible to block now.
The second addition is a ton more context. In addition to the context we talked about before with the prompt, then the knowledge, product catalog and web index, the Agentic browser now knows:
Your open tabs and what’s going on in them.
Your browser history
Your email (you can inference order history from this)
Your calendar
Your autofill data (passwords, credit cards, bill-to, ship-to )
Agentic Browser assets
To summarize the Agentic Browser has:
Training data - The entire Worlds data but months old, foundation of LLM’s knowledge
Web index - Index of the web, days old.
Product Catalog - Built from Web index and merchant center - gives the Agentic Commerce system a complete database of products including availability and pricing. Usually no more than 24hrs old.
Crawler-enabled agent - Server-based agent is able to get real-time information and manipulate web pages as a human would to achieve various objectives.
Browser-based agent (local) -
Complete Browser Context - Tabs, favorites, autofill data, browsing history, email, calendar, etc.
This array of content, context, tools and ‘approaches’ to the data the agent needs to complete tasks on your behalf is super-human level of access and you can really feel it when you start using these browsers.
Unblockable!
Now that the agent is sitting on the users device be it a phone, tablet or desktop, it is much much harder to stop. It identifies as a browser, it has the same IP as the user - blocking the IP shuts the user out of my site, that’s not a great strategy. There maybe ways to fingerprint the user vs. the agent, but they are going to be in the 50-80% accuracy zone, which means lots of false positives - you moved the mouse like a bot, you are shut out of Amazon - another bad user experience. Agentic browsers, therefore, are unblockable. Game over, Checkmate.
The Other Myriad Benefits of Being THE Browser
In addition to the above benefits, you get to be the default search engine and a shot, at install, of being the default browser. You also get to make your web search the default. People are lazy - when they install Chrome, they stick with Google. When they install edge/windows, they stick with Bing and so on.
Remember LLMs love data, content and context. Web crawler data is interesting, but it’s static - you can’t tell which pages are the most popular, demographic data, anything. If you get millions of people using your agentic browser, you can create a much better web crawler by, for example, more frequently crawing the top trafficed pages. You can see click-through rates, purchase rates, lots and lots of VERY useful data for building a variety of better user experiences AND monetization capabilities (marketplaces, ad networks, affiliate models, agentic social media, etc.)
I’m sure there are others I’m missing, but in a world where companies are spending $80B/yr on GPU CAPEX, a browser initiative is easily worth $8-10B. We are at the tip of the iceburg on agentic browser innovation.
Coming tomorrow… Part 2
That’s the end of Part 1 - tomorrow, Part 2 will get into a live demo use case where we pit these browsers against each other to show all of the conceptual concepts we covered above in the real world where things get touch in ecommerce real fast.